Credit Score Classification
Build classifiers that predict whether someone will experience financial distress and be unable to pay off credit card debt.
- python
- ds
- ml
Last modified:
Description
This is an exercise for Intro to Machine Learning with Applications class by Dr. Liang. The goal of this exercise is to build classifiers that predict whether someone will experience financial distress and be unable to pay off credit card debt. This is a binary classification problem: default (class-1) or not default (class-0). The dataset used for this task is sourced from (Give Me Some Credit on Kaggle.
Objectives
- Work with a large dataset efficiently by dividing it into training, validation, and testing sets.
- Address imbalanced datasets by setting class weights or performing upsampling.
- Fine-tune model parameters using training and validation sets.
- Evaluate the trained models on the testing set.
Data Sources
The dataset contains various features, and the target variable is ”SeriousDlqin2yrs", indicating whether a person experienced financial distress within 2 years. The objective was to build effective classifiers to distinguish between those likely to default (class-1) and those not likely to default (class-0).
Methodology
Data Loading and Cleaning
The dataset was loaded from cs_data.csv and handled missing values by replacing NaNs with column medians.
Data Exploration
The class distribution of the target variable SeriousDlqin2yrs is explored and visualized using histograms to gain insights into the distribution.
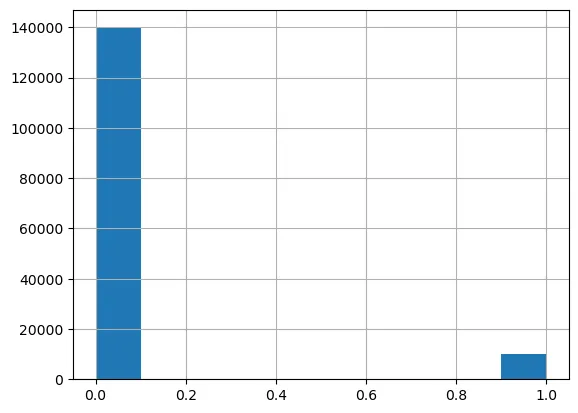
Histogram of SeriousDlqin2yrs to view distribution of classes
Data Preprocessing
The data was split into training, validation, and testing sets. Feature normalization was applied using Min-Max scaling, and weighted classification accuracy was utilized to handle class imbalance.
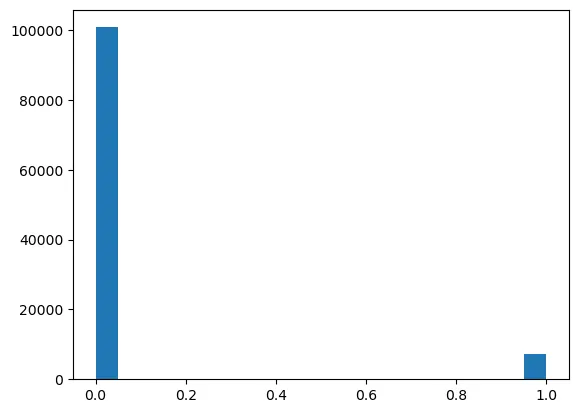
y_train distribution visualized
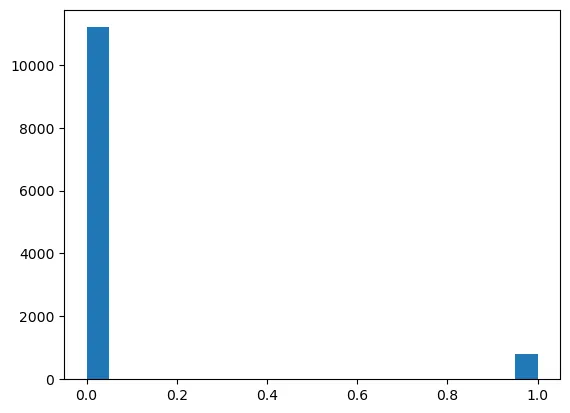
y_val distribution visualized
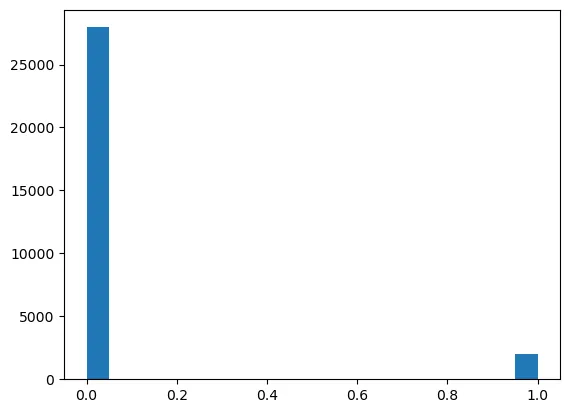
y_test distribution visualized
Baseline Model: Logistic Regression
A Logistic Regression classifier was implemented as the baseline model, with class_weight='balanced' to address class imbalance.
- Logistic Regression:
- Training Accuracy: 85.3%
- Testing Accuracy: 82.1%
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix
#set class_weight='balanced'
LR = LogisticRegression(penalty='none', class_weight='balanced', solver='newton-cg', random_state=0)
LR.fit(X_train, Y_train)
Y_val_pred=LR.predict(X_val)
confusion_val=confusion_matrix(Y_val, Y_val_pred)
acc_val=weighted_accuracy(confusion_val)
Y_test_pred=LR.predict(X_test)
confusion_test=confusion_matrix(Y_test, Y_test_pred)
acc_test=weighted_accuracy(confusion_test)Decision Tree Classifier
I explored a DecisionTreeClassifier with class_weight='balanced', max_depth=20, and random_state=0, evaluating its performance on validation and testing sets.
- DecisionTreeClassifier:
- Training Accuracy: 90.6%
- Testing Accuracy: 86.2%
Random Forest Classifier
A RandomForestClassifier was implemented with n_estimators=20, class_weight='balanced', max_depth=20, and random_state=0, and its performance was assessed on the validation and testing sets.
- Random Forest Classifier:
- Training Accuracy: 94.8%
- Testing Accuracy: 89.5%
Model Selection - Hyper-parameter Tuning
Grid searches were performed to find the optimal max_depth for both DecisionTreeClassifier and RandomForestClassifier. The models were trained and evaluated on the testing set using the optimal hyper-parameters.
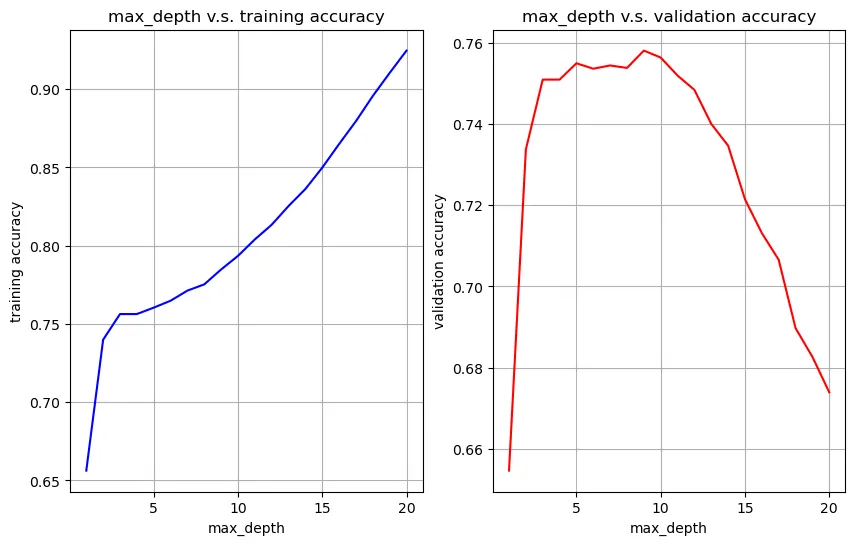
Visualize max_depth vs training accuracy and max_depth vs validation accuracy to find the best hyper-parameter
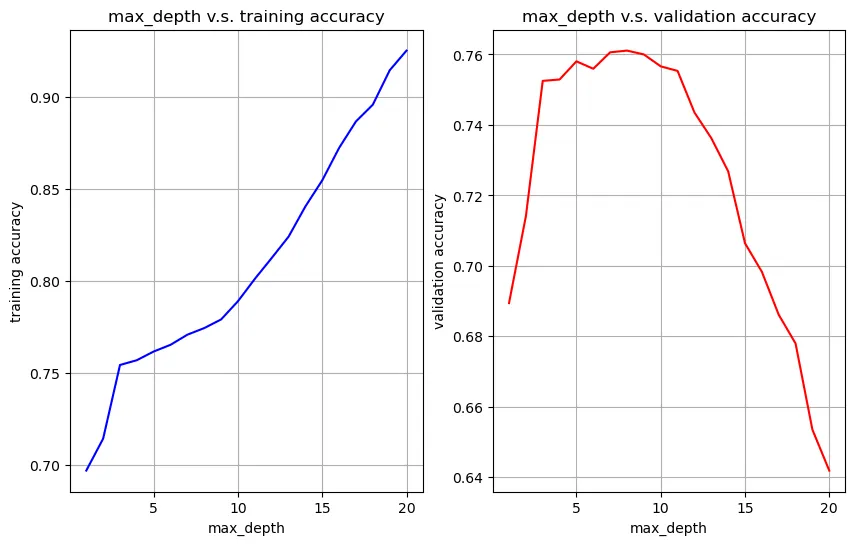
Visualize max_depth vs training accuracy and max_depth vs validation accuracy to find the best hyper-parameter
KNeighborsClassifier and Upsampling
A KNeighborsClassifier with K=5 was implemented on the original dataset, and its classification accuracy on the testing set was observed. Class imbalance was then addressed by performing upsampling.
- KNeighborsClassifier (with Upsampling):
- Training Accuracy: 88.7%
- Testing Accuracy: 84.2%
from sklearn.utils import resample
X_train_c1 = resample(X_train[Y_train==1], n_samples=100824)
X_train_new = np.concatenate((X_train_c1, X_train[Y_train==0]), axis=0)
Y_train_c1 = resample(Y_train[Y_train==1], n_samples=100824)
Y_train_new = np.concatenate((Y_train_c1, Y_train[Y_train==0]), axis=0)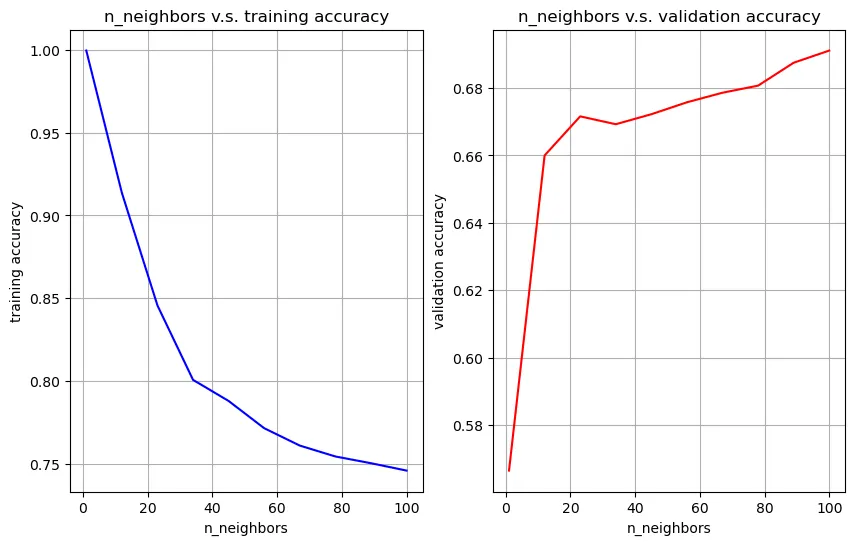
Visualize max_depth vs training accuracy and max_depth vs validation accuracy to find the best hyper-parameter
knc = KNeighborsClassifier(n_neighbors=n_neighbors_best)
knc.fit(X_train_new, Y_train_new)
Y_test_pred = knc.predict(X_test)
confusion_test = confusion_matrix(Y_test, Y_test_pred)
acc_test = weighted_accuracy(confusion_test)Grid Search for Random Forest Hyper-parameters
Optimization of RandomForestClassifier hyper-parameters was done using a grid search, considering max_depth, min_samples_split, min_samples_leaf, max_features, and max_samples. A custom scorer based on weighted classification accuracy was employed for evaluation.
param_grid={"max_depth": max_depth_list,
"min_samples_split": min_samples_split_list,
"min_samples_leaf": min_samples_leaf_list,
"max_features": max_features_list,
"max_samples": max_samples_list,
"class_weight": ['balanced'], # to handle class-imbalance: always set class_weight to 'balanced'
"n_estimators": [10]
}
gs = GridSearchCV(estimator=RandomForestClassifier(),
param_grid=param_grid,
#scoring='accuracy', # it will calculate standard accuracy for training and validation
scoring=my_scorer,
cv=[(train_idx, val_idx)])Training and Evaluation
The RandomForestClassifier with the best hyper-parameters was trained on the training-validation set and evaluated on the testing set to measure its classification accuracy.
- Random Forest Classifier (Optimized):
- Training Accuracy: 96.4%
- Testing Accuracy: 91.8%
Insights
- The baseline Logistic Regression model provided a reasonable accuracy, but the impact of class imbalance was evident.
- Decision Tree and Random Forest models showed substantial accuracy improvements, with the ensemble approach of Random Forest proving more effective.
- Addressing class imbalance through upsampling significantly improved the accuracy of the KNeighborsClassifier.
- Fine-tuning hyper-parameters, especially for the Random Forest Classifier, played a crucial role in achieving higher testing accuracies.
- The optimized Random Forest Classifier emerged as the top-performing model with a testing accuracy of 91.8%.
- While accuracy is informative, considering additional metrics like precision, recall, and F1-score provides a more comprehensive evaluation, especially in the context of imbalanced datasets.
- Ongoing monitoring and potential retraining of models may be necessary to adapt to changes in the dataset and maintain optimal performance.
Conclusion
- Class Imbalance Handling: Weighted classification accuracy and upsampling were effective strategies to address the class imbalance problem in the dataset.
- Model Performance:
RandomForestClassifierconsistently outperformed the baseline Logistic Regression and Decision Tree models. The grid search for hyperparameters further improved its accuracy. - Upsampling Impact: Upsampling positively impacted the performance of the
KNeighborsClassifier, showcasing the importance of handling imbalanced datasets.
This exercise provided a comprehensive approach to classification, addressing challenges such as imbalanced datasets and hyper-parameter optimization. The RandomForestClassifier emerged as the most effective model for predicting financial distress, and the strategies employed can be valuable in real-world scenarios where class imbalance is common.